The Open Distro project is archived. Open Distro development has moved to OpenSearch. The Open Distro plugins will continue to work with legacy versions of Elasticsearch OSS, but we recommend upgrading to OpenSearch to take advantage of the latest features and improvements.
Policies
Policies are JSON documents that define the following:
- The states that an index can be in, including the default state for new indices. For example, you might name your states “hot,” “warm,” “delete,” and so on. For more information, see States.
- Any actions that you want the plugin to take when an index enters a state, such as performing a rollover. For more information, see Actions.
- The conditions that must be met for an index to move into a new state, known as transitions. For example, if an index is more than eight weeks old, you might want to move it to the “delete” state. For more information, see Transitions.
In other words, a policy defines the states that an index can be in, the actions to perform when in a state, and the conditions that must be met to transition between states.
You have complete flexibility in the way you can design your policies. You can create any state, transition to any other state, and specify any number of actions in each state.
This table lists the relevant fields of a policy.
| Field | Description | Type | Required | Read Only |
|---|---|---|---|---|
policy_id | The name of the policy. | string | Yes | Yes |
description | A human-readable description of the policy. | string | Yes | No |
ism_template | Specify an ISM template pattern that matches the index to apply the policy. | nested list of objects | No | No |
last_updated_time | The time the policy was last updated. | timestamp | Yes | Yes |
error_notification | The destination and message template for error notifications. The destination could be Amazon Chime, Slack, or a webhook URL. | object | No | No |
default_state | The default starting state for each index that uses this policy. | string | Yes | No |
states | The states that you define in the policy. | nested list of objects | Yes | No |
Table of contents
- States
- Actions
- ISM supported operations
- Transitions
- Error notifications
- Sample policy with ISM template
- Example policy
States
A state is the description of the status that the managed index is currently in. A managed index can be in only one state at a time. Each state has associated actions that are executed sequentially on entering a state and transitions that are checked after all the actions have been completed.
This table lists the parameters that you can define for a state.
| Field | Description | Type | Required |
|---|---|---|---|
name | The name of the state. | string | Yes |
actions | The actions to execute after entering a state. For more information, see Actions. | nested list of objects | Yes |
transitions | The next states and the conditions required to transition to those states. If no transitions exist, the policy assumes that it’s complete and can now stop managing the index. For more information, see Transitions. | nested list of objects | Yes |
Actions
Actions are the steps that the policy sequentially executes on entering a specific state.
They are executed in the order in which they are defined.
This table lists the parameters that you can define for an action.
| Parameter | Description | Type | Required | Default |
|---|---|---|---|---|
timeout | The timeout period for the action. Accepts time units for minutes, hours, and days. | time unit | No | - |
retry | The retry configuration for the action. | object | No | Specific to action |
The retry operation has the following parameters:
| Parameter | Description | Type | Required | Default |
|---|---|---|---|---|
count | The number of retry counts. | number | Yes | - |
backoff | The backoff policy type to use when retrying. | string | No | Exponential |
delay | The time to wait between retries. Accepts time units for minutes, hours, and days. | time unit | No | 1 minute |
The following example action has a timeout period of one hour. The policy retries this action three times with an exponential backoff policy, with a delay of 10 minutes between each retry:
"actions": {
"timeout": "1h",
"retry": {
"count": 3,
"backoff": "exponential",
"delay": "10m"
}
}
For a list of available unit types, see Supported units.
ISM supported operations
ISM supports the following operations:
- force_merge
- read_only
- read_write
- replica_count
- close
- open
- delete
- rollover
- notification
- snapshot
- index_priority
- allocation
force_merge
Reduces the number of Lucene segments by merging the segments of individual shards. This operation attempts to set the index to a read-only state before starting the merging process.
| Parameter | Description | Type | Required |
|---|---|---|---|
max_num_segments | The number of segments to reduce the shard to. | number | Yes |
{
"force_merge": {
"max_num_segments": 1
}
}
read_only
Sets a managed index to be read only. When an index is read only it doesn’t refresh.
{
"read_only": {}
}
read_write
Sets a managed index to be writeable.
{
"read_write": {}
}
replica_count
Sets the number of replicas to assign to an index.
| Parameter | Description | Type | Required |
|---|---|---|---|
number_of_replicas | Defines the number of replicas to assign to an index. | number | Yes |
{
"replica_count": {
"number_of_replicas": 2
}
}
For information about setting replicas, see Primary and replica shards.
close
Closes the managed index.
{
"close": {}
}
Closed indices remain on disk, but consume no CPU or memory. You can’t read from, write to, or search closed indices.
Closing an index is a good option if you need to retain data for longer than you need to actively search it and have sufficient disk space on your data nodes. If you need to search the data again, reopening a closed index is simpler than restoring an index from a snapshot.
open
Opens a managed index.
{
"open": {}
}
delete
Deletes a managed index.
{
"delete": {}
}
rollover
Rolls an alias over to a new index when the managed index meets one of the rollover conditions.
The index format must match the pattern: ^.*-\d+$. For example, (logs-000001). Set index.opendistro.index_state_management.rollover_alias as the alias to rollover.
| Parameter | Description | Type | Example | Required |
|---|---|---|---|---|
min_size | The minimum size of the total primary shard storage (not counting replicas) required to roll over the index. For example, if you set min_size to 100 GiB and your index has 5 primary shards and 5 replica shards of 20 GiB each, the total size of all primary shards is 100 GiB, so the rollover occurs. ISM doesn’t check indices continually, so it doesn’t roll over indices at exactly 100 GiB. Instead, if an index is continuously growing, ISM might check it at 99 GiB, not perform the rollover, check again when the shards reach 105 GiB, and then perform the operation. | string | 20gb or 5mb | No |
min_doc_count | The minimum number of documents required to roll over the index. | number | 2000000 | No |
min_index_age | The minimum age required to roll over the index. Index age is the time between its creation and the present. | string | 5d or 7h | No |
{
"rollover": {
"min_size": "50gb"
}
}
{
"rollover": {
"min_doc_count": 100000000
}
}
{
"rollover": {
"min_index_age": "30d"
}
}
notification
Sends you a notification.
| Parameter | Description | Type | Required |
|---|---|---|---|
destination | The destination URL. | Slack, Amazon Chime, or webhook URL | Yes |
message_template | The text of the message. You can add variables to your messages using Mustache templates. | object | Yes |
The destination system must return a response otherwise the notification operation throws an error.
Example 1: Chime notification
{
"notification": {
"destination": {
"chime": {
"url": "<url>"
}
},
"message_template": {
"source": "the index is {{ctx.index}}"
}
}
}
Example 2: Custom webhook notification
{
"notification": {
"destination": {
"custom_webhook": {
"url": "https://<your_webhook>"
}
},
"message_template": {
"source": "the index is {{ctx.index}}"
}
}
}
Example 3: Slack notification
{
"notification": {
"destination": {
"slack": {
"url": "https://hooks.slack.com/services/xxx/xxxxxx"
}
},
"message_template": {
"source": "the index is {{ctx.index}}"
}
}
}
You can use ctx variables in your message to represent a number of policy parameters based on the past executions of your policy. For example, if your policy has a rollover action, you can use {{ctx.action.name}} in your message to represent the name of the rollover.
The following ctx variable options are available for every policy:
Guaranteed variables
| Parameter | Description | Type |
|---|---|---|
index | The name of the index. | string |
index_uuid | The uuid of the index. | string |
policy_id | The name of the policy. | string |
snapshot
Backup your cluster’s indices and state. For more information about snapshots, see Take and restore snapshots.
The snapshot operation has the following parameters:
| Parameter | Description | Type | Required | Default |
|---|---|---|---|---|
repository | The repository name that you register through the native snapshot API operations. | string | Yes | - |
snapshot | The name of the snapshot. | string | Yes | - |
{
"snapshot": {
"repository": "my_backup",
"snapshot": "my_snapshot"
}
}
index_priority
Set the priority for the index in a specific state. Unallocated shards of indices are recovered in the order of their priority, whenever possible. The indices with higher priority values are recovered first followed by the indices with lower priority values.
The index_priority operation has the following parameter:
| Parameter | Description | Type | Required | Default |
|---|---|---|---|---|
priority | The priority for the index as soon as it enters a state. | number | Yes | 1 |
"actions": [
{
"index_priority": {
"priority": 50
}
}
]
allocation
Allocate the index to a node with a specific attribute. For example, setting require to warm moves your data only to “warm” nodes.
The allocation operation has the following parameters:
| Parameter | Description | Type | Required |
|---|---|---|---|
require | Allocate the index to a node with a specified attribute. | string | Yes |
include | Allocate the index to a node with any of the specified attributes. | string | Yes |
exclude | Don’t allocate the index to a node with any of the specified attributes. | string | Yes |
wait_for | Wait for the policy to execute before allocating the index to a node with a specified attribute. | string | Yes |
"actions": [
{
"allocation": {
"require": { "box_type": "warm" }
}
}
]
Transitions
Transitions define the conditions that need to be met for a state to change. After all actions in the current state are completed, the policy starts checking the conditions for transitions.
Transitions are evaluated in the order in which they are defined. For example, if the conditions for the first transition are met, then this transition takes place and the rest of the transitions are dismissed.
If you don’t specify any conditions in a transition and leave it empty, then it’s assumed to be the equivalent of always true. This means that the policy transitions the index to this state the moment it checks.
This table lists the parameters you can define for transitions.
| Parameter | Description | Type | Required |
|---|---|---|---|
state_name | The name of the state to transition to if the conditions are met. | string | Yes |
conditions | List the conditions for the transition. | list | Yes |
The conditions object has the following parameters:
| Parameter | Description | Type | Required |
|---|---|---|---|
min_index_age | The minimum age of the index required to transition. | string | No |
min_doc_count | The minimum document count of the index required to transition. | number | No |
min_size | The minimum size of the total primary shard storage (not counting replicas). For example, if you set min_size to 100 GiB and your index has 5 primary shards and 5 replica shards of 20 GiB each, the total size of all primary shards is 100 GiB, so your index is transitioned to the next state. | string | No |
cron | The cron job that triggers the transition if no other transition happens first. | object | No |
cron.cron.expression | The cron expression that triggers the transition. | string | Yes |
cron.cron.timezone | The timezone that triggers the transition. | string | Yes |
The following example transitions the index to a cold state after a period of 30 days:
"transitions": [
{
"state_name": "cold",
"conditions": {
"min_index_age": "30d"
}
}
]
ISM checks the conditions on every execution of the policy based on the set interval.
This example uses the cron condition to transition indices every Saturday at 5:00 PT:
"transitions": [
{
"state_name": "cold",
"conditions": {
"cron": {
"cron": {
"expression": "* 17 * * SAT",
"timezone": "America/Los_Angeles"
}
}
}
}
]
Note that this condition does not execute at exactly 5:00 PM; the job still executes based off the job_interval setting. Due to this variance in start time and the amount of time that it can take for actions to complete prior to checking transition conditions, we recommend against overly narrow cron expressions. For example, don’t use 15 17 * * SAT (5:15 PM on Saturday).
A window of an hour, which this example uses, is generally sufficient, but you might increase it to 2–3 hours to avoid missing the window and having to wait a week for the transition to occur. Alternately, you could use a broader expression such as * * * * SAT,SUN to have the transition occur at any time during the weekend.
For information on writing cron expressions, see Cron expression reference.
Error notifications
The error_notification operation sends you a notification if your managed index fails. It notifies a single destination with a custom message.
Set up error notifications at the policy level:
{
"policy": {
"description": "hot warm delete workflow",
"default_state": "hot",
"schema_version": 1,
"error_notification": { },
"states": [ ]
}
}
| Parameter | Description | Type | Required |
|---|---|---|---|
destination | The destination URL. | Slack, Amazon Chime, or webhook URL | Yes |
message_template | The text of the message. You can add variables to your messages using Mustache templates. | object | Yes |
The destination system must return a response otherwise the error_notification operation throws an error.
Example 1: Chime notification
{
"error_notification": {
"destination": {
"chime": {
"url": "<url>"
}
},
"message_template": {
"source": "The index {{ctx.index}} failed during policy execution."
}
}
}
Example 2: Custom webhook notification
{
"error_notification": {
"destination": {
"custom_webhook": {
"url": "https://<your_webhook>"
}
},
"message_template": {
"source": "The index {{ctx.index}} failed during policy execution."
}
}
}
Example 3: Slack notification
{
"error_notification": {
"destination": {
"slack": {
"url": "https://hooks.slack.com/services/xxx/xxxxxx"
}
},
"message_template": {
"source": "The index {{ctx.index}} failed during policy execution."
}
}
}
You can use the same options for ctx variables as the notification operation.
Sample policy with ISM template
The following sample template policy is for a rollover use case.
-
Create a policy with an
ism_templatefield:PUT _opendistro/_ism/policies/rollover_policy { "policy": { "description": "Example rollover policy.", "default_state": "rollover", "states": [ { "name": "rollover", "actions": [ { "rollover": { "min_doc_count": 1 } } ], "transitions": [] } ], "ism_template": { "index_patterns": ["log*"], "priority": 100 } } }You need to specify the
index_patternsfield. If you don’t specify a value forpriority, it defaults to 0. -
Set up a template with the
rollover_aliasaslog:PUT _index_template/ism_rollover { "index_patterns": ["log*"], "settings": { "opendistro.index_state_management.rollover_alias": "log" } } -
Create an index with the
logalias:PUT log-000001 { "aliases": { "log": { "is_write_index": true } } } -
Index a document to trigger the rollover condition:
POST log/_doc { "message": "dummy" }
Example policy
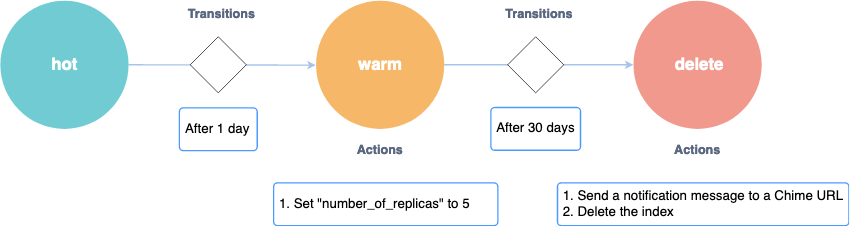
The following example policy implements a hot, warm, and delete workflow. You can use this policy as a template to prioritize resources to your indices based on their levels of activity.
In this case, an index is initially in a hot state. After a day, it changes to a warm state, where the number of replicas increases to 5 to improve the read performance.
After 30 days, the policy moves this index into a delete state. The service sends a notification to a Chime room that the index is being deleted, and then permanently deletes it.
{
"policy": {
"description": "hot warm delete workflow",
"default_state": "hot",
"schema_version": 1,
"states": [
{
"name": "hot",
"actions": [
{
"rollover": {
"min_index_age": "1d"
}
}
],
"transitions": [
{
"state_name": "warm"
}
]
},
{
"name": "warm",
"actions": [
{
"replica_count": {
"number_of_replicas": 5
}
}
],
"transitions": [
{
"state_name": "delete",
"conditions": {
"min_index_age": "30d"
}
}
]
},
{
"name": "delete",
"actions": [
{
"notification": {
"destination": {
"chime": {
"url": "<URL>"
}
},
"message_template": {
"source": "The index {{ctx.index}} is being deleted"
}
}
},
{
"delete": {}
}
]
}
]
}
}
This diagram shows the states, transitions, and actions of the above policy as a finite-state machine. For more information about finite-state machines, see Wikipedia.